



Embeddings have become a core tool in AI applications to determine semantic similarity between pieces of content. Developers are using embeddings for various tasks, such as search, retrieval augmented generation, and clustering.
At Supabase, we support storing embeddings in Postgres using the pgvector extension. pgvector adds a new datatype vector, which developers use to store embeddings in regular columns within their database tables. Similarity can be calculated between these vectors using one of the three supported distance measures:
- Inner product
- Cosine distance
- Euclidean distance
Challenges with pgvector
Without indexes, pgvector performs a full table scan when you run a similarity query. This means distance has to be computed against every row in your table. This is manageable at a small scale but becomes problematic as your table grows.
To solve this, pgvector offers indexes. Indexes reorganize the data into data structures that exploit internal structure and enable approximate similarity search without referring to every record. Currently, pgvector supports an IVF index, with HNSW expected in the next release.
IVF indexes work by clustering vectors into lists, and then querying only vectors within the same list (or multiple nearby lists, depending on the value of probes).
Scaling indexes
98% of our customers are generating text embeddings using OpenAI's text-embedding-ada-002 model. At an initial glance, there's good reason for this - these embeddings perform quite well for information retrieval and are economical to produce. text-embedding-ada-002 produces vectors with 1536 dimensions which is among the largest in the industry. IVF indexes help address some scaling challenges, but there are still some pitfalls.
First, vectors are large. A 1536 dimensional vector is ~12.3 kilobytes. Scaling that up to 1M vectors, the raw data tops 11 gigabytes. Experienced SQL users know that for best performance, indexes should fit within system memory. Moreover, unlike traditional workloads, there is a significant compute component when performing vector similarity queries.
In the real-world it's common for an index to reduce the number of distance computations needed to estimate nearest neighbors from 100% of the dataset to 5-20%. At 1M records, that's still 50k-200k distance calculations being performed for a single query. Given how different the resource requirements are to support heavy vector workloads, it's not surprising that one of the most common issues we see is significant under provisioning of hardware.
Massive Text Embedding Benchmark (MTEB)
Text embeddings are one of the most common types of embeddings today. Our friends at Hugging Face have done the hard work of comparing text embedding models (including OpenAI's text-embedding-ada-002) by benchmarking them against common similarity tasks:
- Retrieval (search)
- Semantic textual similarity (STS)
- Classification
- Clustering
- Pair classification
- Reranking
- Summarization
- Bitext mining
Models are ranked per task by taking their average score produced over each task's datasets. Each model also has an overall (general purpose) score, calculated by taking the average score produced across all datasets. You can find the results on their MTEB leaderboard.
It's worth pointing out that each model's dimension size has little-to-no correlation with its performance. In fact, there are a number of models that perform comparably withtext-embedding-ada-002, all of which produce embeddings with fewer dimensions than 1536.
| Rank | Model | Dimensions | Average | Model Size (GB) |
|---|---|---|---|---|
| 1 | gte-large | 1024 | 63.13 | 0.67 |
| 2 | gte-base | 768 | 62.39 | 0.22 |
| 3 | e5-large-v2 | 1024 | 62.25 | 1.34 |
| 9 | gte-small | 384 | 61.36 | 0.07 |
| 10 | text-embedding-ada-002 | 1536 | 60.99 | - |
| 12 | e5-small-v2 | 384 | 59.93 | 0.13 |
| 32 | all-MiniLM-L6-v2 | 384 | 56.26 | 0.09 |
Benefits of fewer dimensions
What specifically do we gain when we have fewer dimensions? Faster queries and less RAM: Fewer dimensions mean less computation while more of the dataset or index is able to fit in memory.
Take a look at dot product for example:
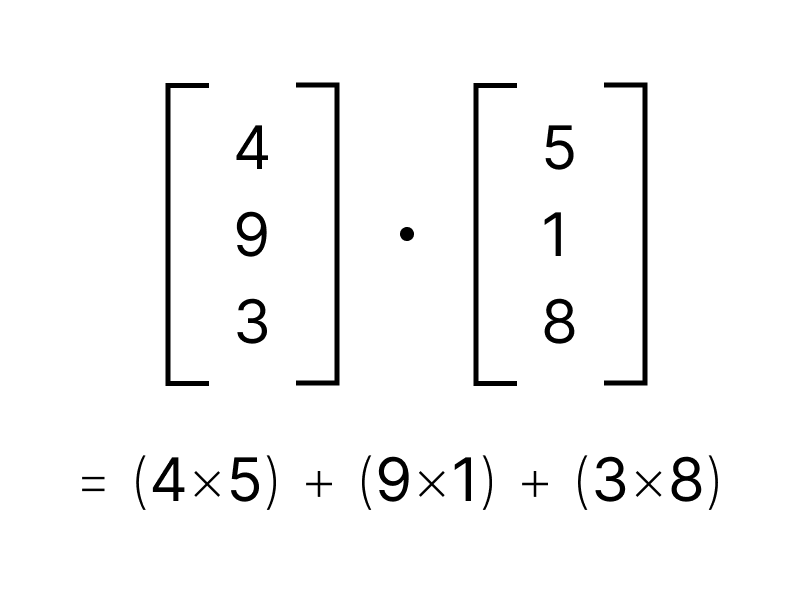
Dot product is the product of each vector element pair summed together into a single result. Fewer dimensions in the vector means fewer calculations for every computed distance.
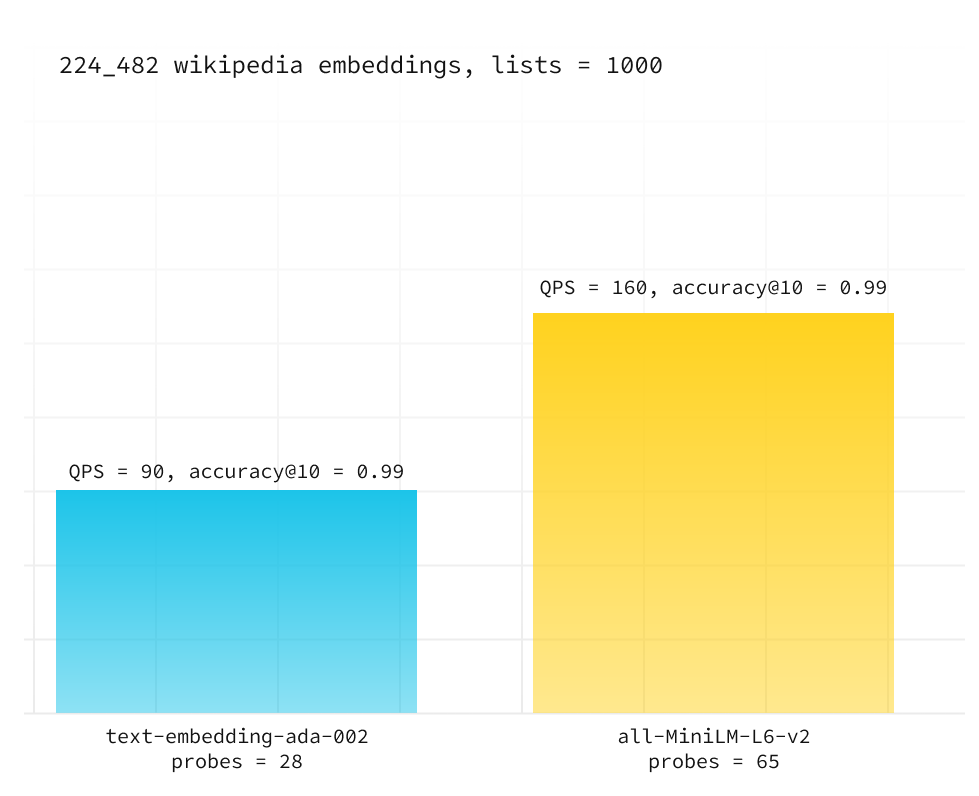
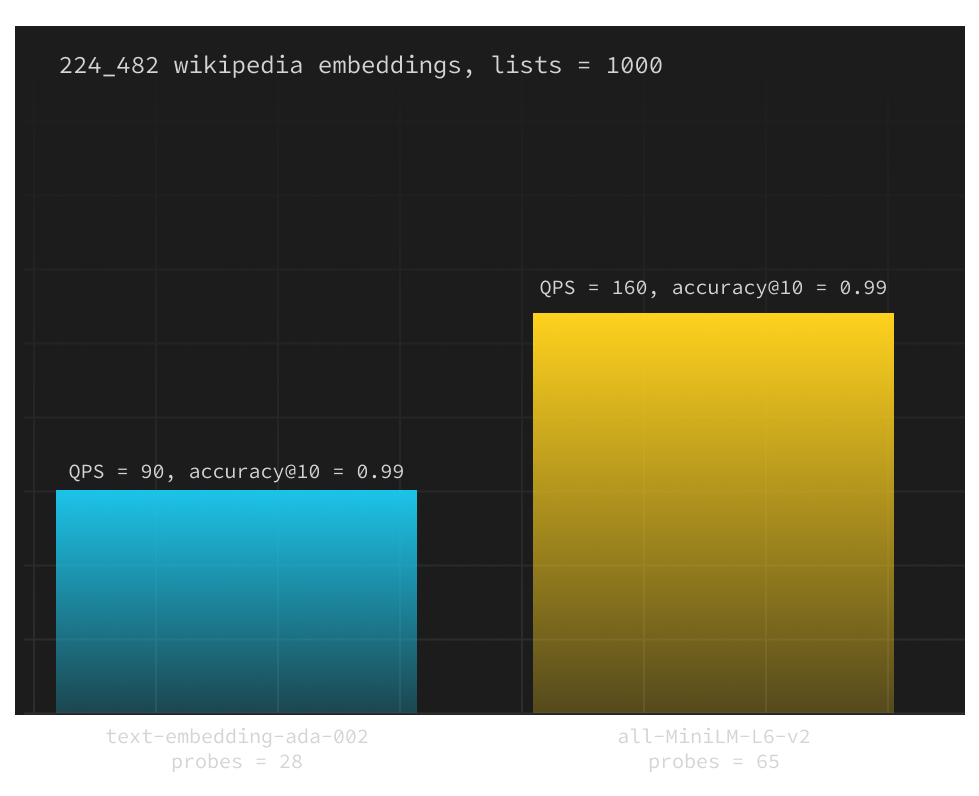
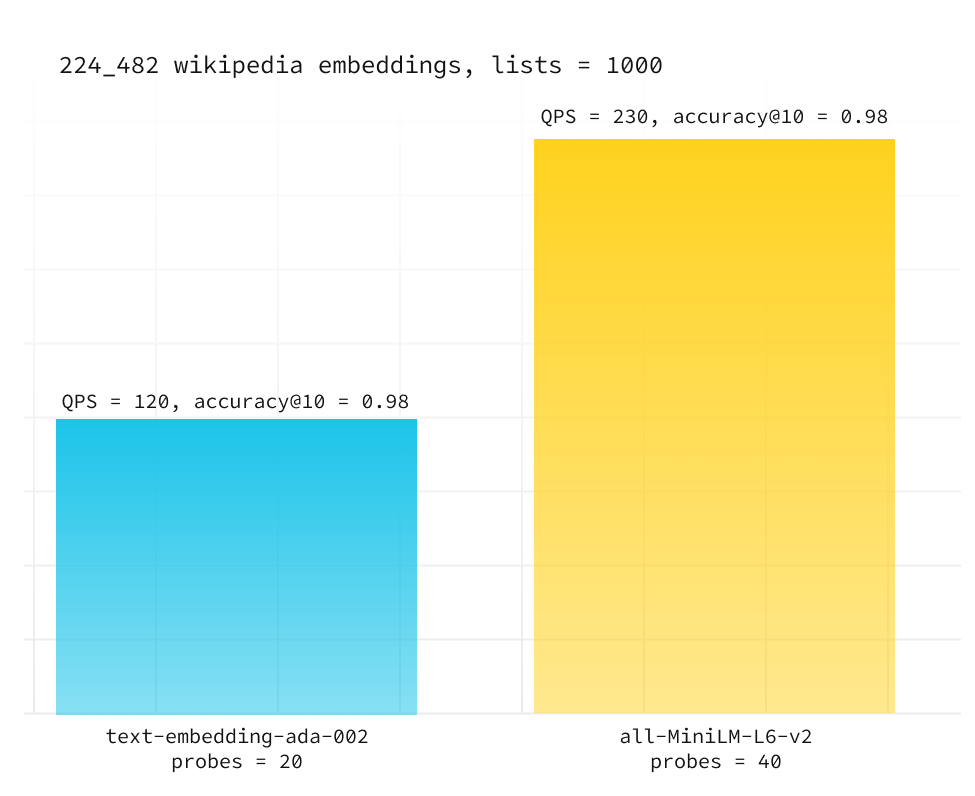
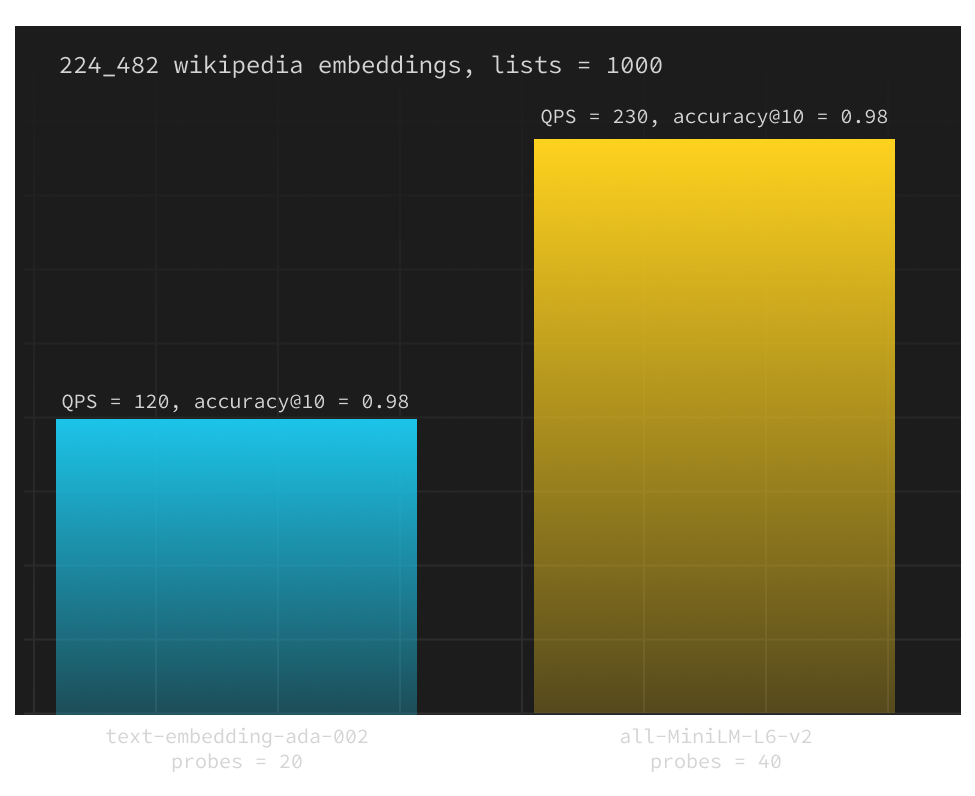
We compared the performance of text-embedding-ada-002 from OpenAI (1536 dimensions) with open-source all-MiniLM-L6-v2 (384 dimensions) by measuring queries per second at a constant accuracy and configuration:
- Database size: with 2vCPU (ARM) and 8GB RAM -
largeadd-on for Supabase project. - Version: Postgres v15 and pgvector v0.4.0
- Dataset: 224,482 embeddings from Wikipedia articles.
- Index: The index was generated for
inner-product(dot product) distance function withlists=1000. - Process: We followed our optimization guide and tips.
We observed pgvector with all-MiniLM-L6-v2 outperforming text-embedding-ada-002 by 78% when holding the accuracy@10 constant at 0.99. This gap increases as you lower the accuracy. Postgres was using just 4GB of RAM with 384d vectors generated by all-MiniLM-L6-v2 compared to 7.5GB with text-embedding-ada-002.
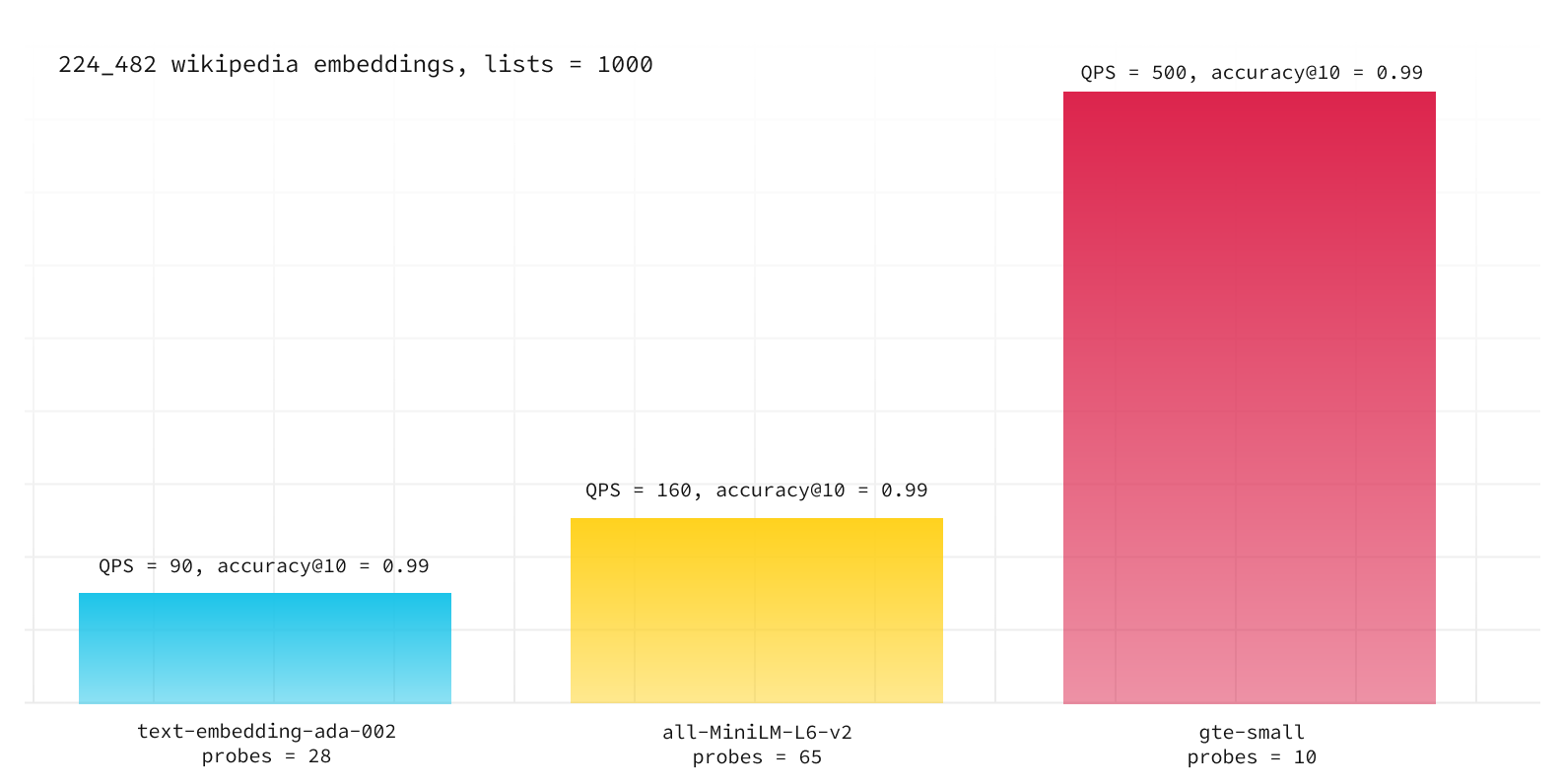
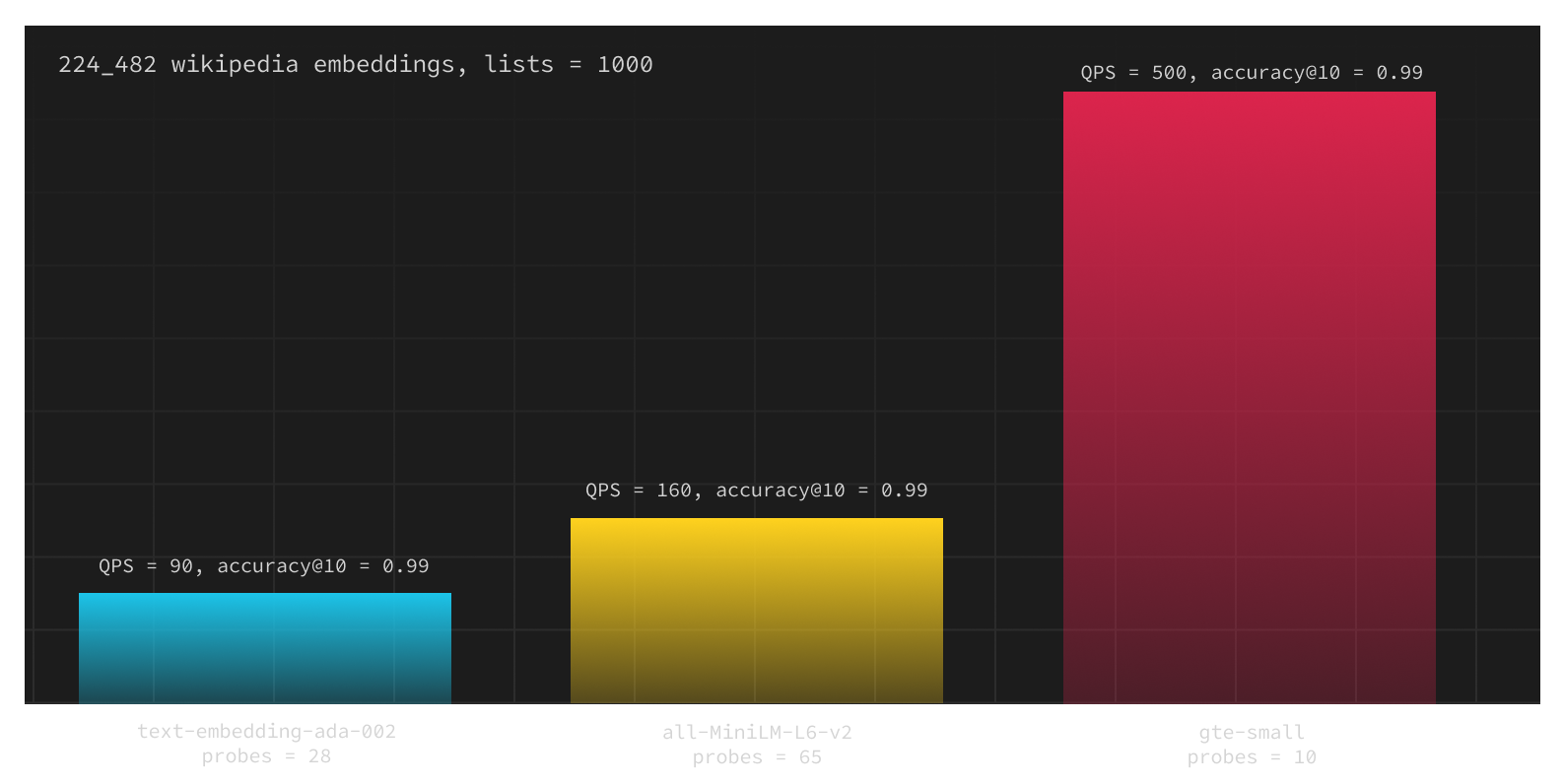
After that, we decided to try the recently published gte-small (also 384 dimensions), and the results were even more astonishing. With gte-small, we could set probes=10 to achieve the same level of accuracy@10 = 0.99. Consequently, we observed more than a 200% improvement in queries per second for pgvector with embeddings generated by gte-small compared to all-MiniLM-L6-v2.
Choosing an embedding model
Ultimately the choice of embedding model will depend on your specific use case and requirements. You would likely want to consider:
- Similarity performance: How well do embeddings match based on the task (MTEB score)?
- Model size: What are the operational costs of storing and loading this model into memory?
- Sequence length: How many input tokens does the model support?
- Dimension size: What is the operational cost of storing and comparing embeddings?
- Language: Which written languages do you need to support? Many of the smaller models only support English.
The goal is to maximize similarity performance and sequence length while minimizing model size and dimension size. Notably, if we can find a model that performs well while producing as few dimensions as possible, we can immediately improve many of the above challenges developers are facing with pgvector.
For example gte-small, a model recently trained by the Alibaba DAMO Academy, produces only 384 dimensions while ranking higher than text-embedding-ada-002 on the MTEB leaderboard.
It's worth noting that many models today are trained on English-only text (such as gte-small and all-MiniLM-L6-v2). If you need to work with other languages, be sure to choose a model that supports them, such as multilingual-e5-small.
The best of both worlds
It's important to keep in mind that using an alternative embedding model doesn't preclude using OpenAI for other tasks like text or chat generation. If your application uses embeddings for retrieval augmented generation (searching your knowledge base for additional context to pass to a LLM prompt), you can use a lower dimension embedding model for data fetching, then send the plain text to OpenAI's completion models. The retrieval step is completely decoupled from the LLM generation.
Why not dimensionality reduction?
While dimensionality reduction techniques like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) may seem like a good alternative to trim down the size of text embedding vectors, there is some risk to consider.
First, these tools may not appropriately model the relationships in high-dimensional space. Both PCA and t-SNE are likely to oversimplify the multivariate relationships among different dimensions, leading to the loss of important semantic information. This is particularly the case with PCA, which assumes linearity and would fail to preserve nonlinear interactions found in high-dimensional text embeddings.
Additionally, the validity of the dimensionality reduction models could change over time if the distribution of text data shifts. If the model was trained on older data, it might not accurately reflect or accommodate these shifts. For example, if your company gets a large new customer in the legal field and your embedding dataset contained no legal documents when the dimensionality reduction model was trained, otherwise exploitable structure may be destructively compressed. Both PCA and t-SNE are not inherently adaptable to such changes, which could result in an increasingly poor fit over time. In summary, the derived low-dimensional representations may not maintain semantic coherence of the original high-dimensional vectors.
What's next?
At Supabase we are working on ways to make it easy to generate embeddings using open source, high performance, and low dimension embedding models. Stay tuned for Launch Week 8 next week!