

We helped a customer recently who was storing 500 million chat messages in a single Postgres table. As the table was growing, their queries were slowing down.
The simple solution we offered was table partitioning. The difficulty was creating the partitions and migrating the data without blocking queries and downtime. This post explores the method we used to solve this - Dynamic Table Partitioning.
Why Partition Data? The Large Table Problem
When small projects get big, millions of rows can quickly grow to billions of rows. This presents several challenges when storing data in a single table:
- SELECTs get slower as an index grows. The most common index type in Postgres is a btree, which is a tree like structure. To find a row, that tree must be "walked" from the root to the appropriate leaf node where the new values exist. The larger the index, the more nodes need to be traversed.
- INSERTs get slower as an index grows. For many of the same reasons that SELECTs get slower, indexes must again be "walked" to find leaf nodes where a value needs to be inserted. If the leaf node is fully occupied, new nodes must be added. The larger a table gets, the longer this process takes.
- Data can become less relevant. The utility of real-world data often decreases with time. For example, chat messages are most useful when they sent, but over time the frequency that you a user will read them decreases. Old chat messages take up space in your table, and querying new chat messages suffers as a result.
- Large tables mix unrelated data. Often unrelated data is stored together, and so a select statement needs to scan through many irrelevant rows. Using our chat example: maybe it's unusual for users from one organization to be chatting with a different organization. It would be better if each organizations data was split into separate blocks of storage.
- Large tables prevent vacuum operations from completing. Vacuuming is one of the most mysterious aspects of Postgres. Due to the concurrency model of Postgres (MVCC) updated or deleted rows are not immediately removed from storage, but instead are marked deleted. In the background, Postgres will occasionally remove these "dead" rows and reclaim their storage for newly updated or inserted rows. The bigger a table gets, the longer this vacuuming process can take. If your table is being updated frequently it can block this process from completing successfully.
- Large tables mean more data to move around. Usually to test new features you don't need all of your production data, just a small subset of it. Perhaps you only need a month of analytics data, or a day of chats. By partitioning your data into smaller chunks, you can choose to load just enough that you need to run the test you have in mind. This pattern is called Incremental Data Loading.
- Archiving older data is easier done in well defined partitions. The flip side of the incremental data loading problem is incremental archiving. Old data often become so irrelevant that it cost prohibitive to keep it in live database tables. By using dynamic partitioning older partitions can be detached and archived into a cheaper “cold storage” and then loaded again and re-attached only as needed.
Starting small but getting big
A common growing pain for small startups is that they start their database model in a very simple and straightforward way, but then their popularity explodes and so does the amount of data they need to store. Postgres is good at handling millions of rows in a single table, but often there is that one table in a system, the “Large Table”, that grows at a daily rate into hundreds of millions of rows.
Partitioning is a simple solution, but for Postgres this usually requires setting up the partitions at the same time that you create your tables. The challenge is figuring out how to create the partitions after you have millions of rows in your database, and how to migrate those existing rows into your new partitioning scheme with minimal downtime.
Let’s explore a working example showing how to escape this situation using dynamic table partitioning. We’ll setup a simulated “chat app” that has to store possibly millions of chat messages per day. The first step is to set up a fake “Large Table” problem to simulate a data set that has grown past where Postgres can handle it all in one table. So first, we’ll add a couple of new tables for our example chat app:
_15CREATE TABLE chats(_15 id bigserial,_15 created_at timestamptz NOT NULL DEFAULT now(),_15 PRIMARY KEY (id)_15);_15_15CREATE TABLE chat_messages(_15 id bigserial,_15 created_at timestamptz NOT NULL,_15 chat_id bigint NOT NULL,_15 chat_created_at timestamptz NOT NULL,_15 message text NOT NULL,_15 PRIMARY KEY (id),_15 FOREIGN KEY (chat_id) REFERENCES chats(id)_15);
The first table holds chats which are conversations between parties in the app, and the second table holds chat_messages which are the individual messages sent back-and-forth in the chat. Notice that in this example, we don’t include any columns to describe the sender or receivers of these chats for simplicity’s sake, that problem is left up to you to solve, but would likely involve some kind of foreign key references from the chats table to your user tables in an application. Here we are only interested in the structure of the message storage itself.
Next we have to synthesize some fake data. We’ll INSERT some chat rows over a span of time, and then INSERT some chat messages into those chats. You can tweak how much data is created by adjusting the “beginning” and “end” timestamps below. We’re only setting up one month of data but you can increase the timespan or decreasing the one hour interval between chats for more rows.
_29INSERT INTO chats (created_at)_29SELECT generate_series(_29 '2022-01-01'::timestamptz,_29 '2022-01-30 23:00:00'::timestamptz,_29 interval '1 hour'_29);_29_29INSERT INTO chat_messages (_29 created_at,_29 chat_id,_29 chat_created_at,_29 message_29)_29SELECT_29 mca,_29 chats.id,_29 chats.created_at,_29 (SELECT ($$[0:2]={'hello','goodbye','I would like a sandwich please'}$$::text[])[trunc(random() * 3)::int])_29FROM chats_29CROSS JOIN LATERAL (_29 SELECT generate_series(_29 chats.created_at,_29 chats.created_at + interval '1 day',_29 interval '1 minute'_29 ) AS mca_29) b;_29_29CREATE INDEX ON chats (created_at);_29CREATE INDEX ON chat_messages (created_at);
Dynamic partitioning with pl/pgSQL
Next we’ll show a simple partitioning strategy that provides a starting point for your own partitioning tooling using the above “Large Table” fake data, using some of the partitioning patterns described in the Intro above.
First, we should explain Postgres table partitioning a bit more. A Partitioned table can be thought of as a “parent” table with a bunch of “children” tables that are “attached” to it. By breaking one large table into many smaller tables, there are many performance and administrative benefits. When you query a partitioned table, you query the parent table just like you would any other Postgres table, but internally, Postgres knows how to delegate those queries down to the children in the most optimal way.
Child tables are partitioned by some key column in the rows of data that they store. In our “chat” example, this key will be the created_at timestamp. We’ll partition the day into “daily” partitions, so that each child table holds one day’s worth of chat messages. When you create a new child partition table, you must tell Postgres what the range of dates are that the table will hold, this is how Postgres knows where to store and find chat messages in partitions. You’ll see how in our examples below, our child partition table names contain the date of the day that the partition holds, so chats_2023-08-03 is a child partition table for August 3rd, 2023.
If you query the parent tables but do not provide a WHERE clause value for the creation date or range of dates you are looking for, then Postgres must look in all the child tables, this can take some time for lots of data, so make sure you’re always trying to constrain your queries by small range of time so that Postgres can optimize finding that data by looking in the minimum number of child partitions necessary.
In our example below, we will be copying lots of existing chat messages out of one big table into new partitions that we will be creating “on the fly” so to speak, so we must make sure that the rows we insert into each new child partition fall into the right day’s time range. This per-child range of time is called the partitioning constraint. When we copy data into the new tables, we will use a trick by first creating a check constraint that will force Postgres to make sure that the constraint holds for every row, it will throw an error if you try to put a row outside of a child’s partition constraint range.
After we have pre-loaded a new child table with copied rows and verified that the rows are valid with a check constraint, then we can attach the partition to the parent table with ATTACH PARTITION ... command. This will make the new range of child data available for queries on the parent table.
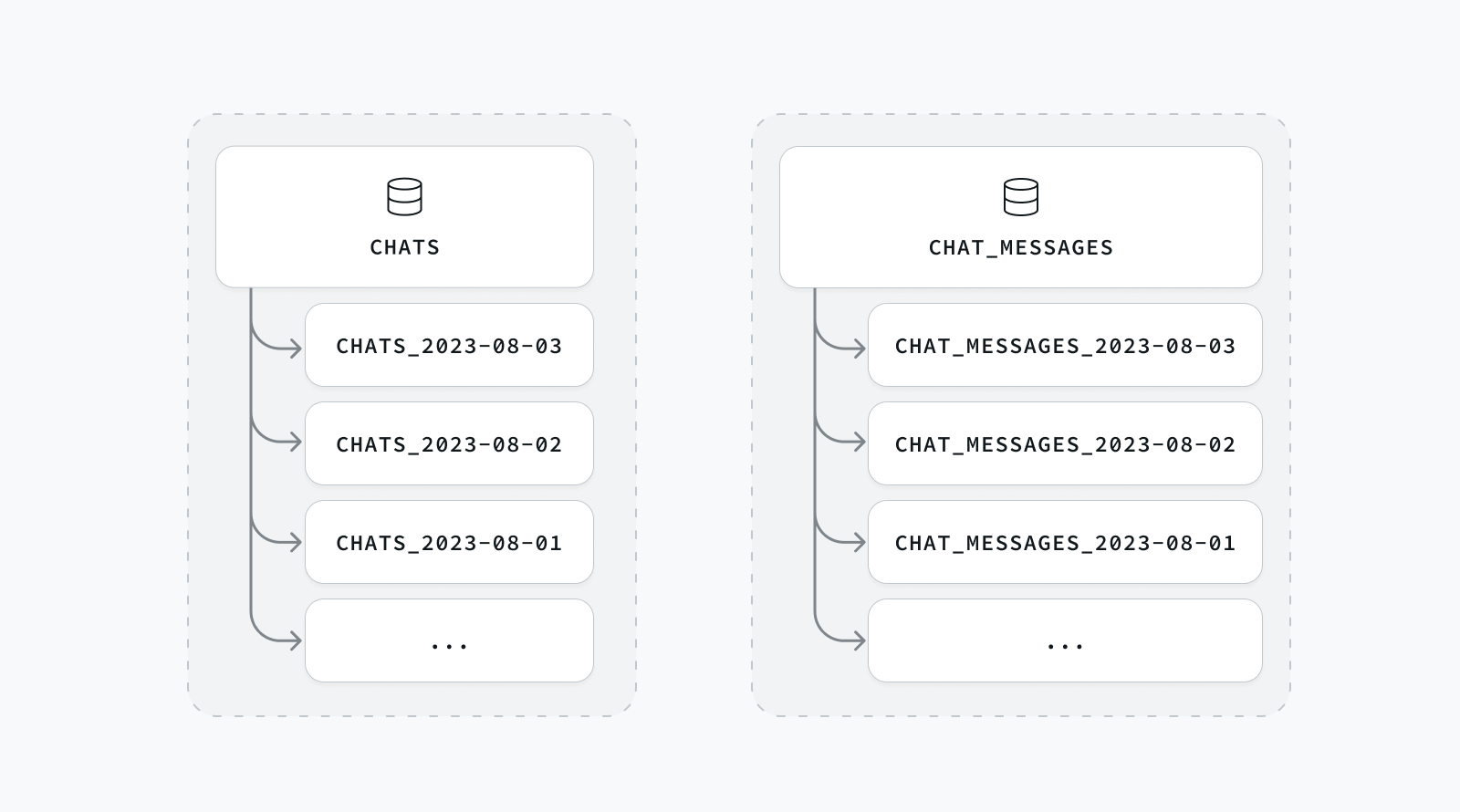
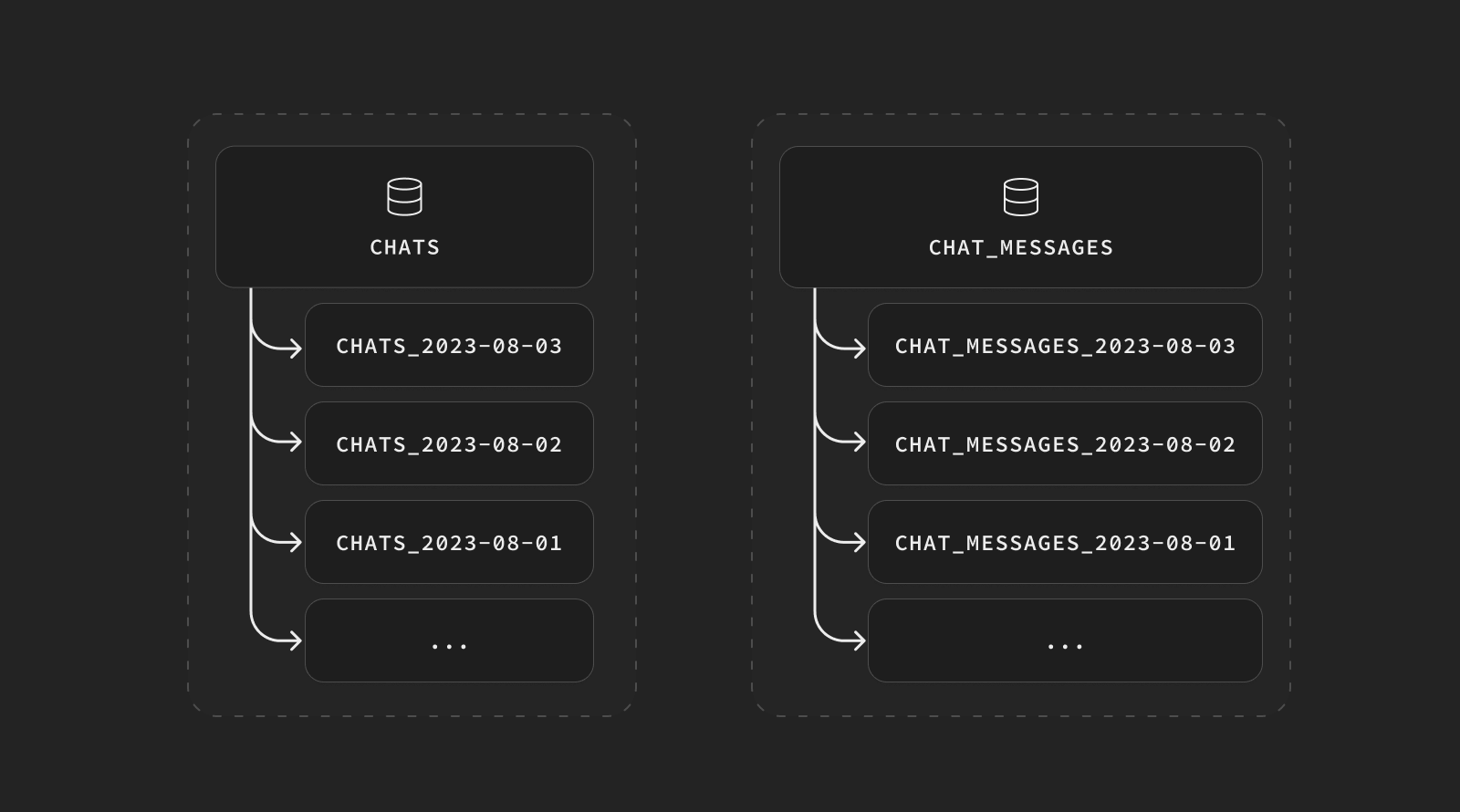
Postgres partitioning became significantly easier in recent versions. Postgres added the new syntax for Declarative Partitioning that makes it easy to create new partitions by adding additional details to your CREATE TABLE statements:
_10CREATE TABLE measurement (_10city_id int not null,_10logdate date not null,_10peaktemp int,_10unitsales int_10) PARTITION BY RANGE (logdate);
But in many cases like those discussed above, there are some wrinkles to simple partitioning that can end up blocking queries if you want to first pre-load data into a partition before attaching it to a parent. So there are in general two approaches, a new child can be declared when the table is created, but it must be empty.
The approach described in this post is that a standalone table is created, filed with data, and then “attached” to the parent table, but this option has a downside if it is not done carefully: if the newly filled table is not setup properly, Postgres will lock the parent table with an EXCLUSIVE ACCESS lock that prevents queries while Postgres ensure that the new partition only contains data that falls within the partitions data range, called a partition constraint. In order to avoid this locking, this constraint must first be added to the standalone table so that Postgres does not need to scan it first.
For example if you partition your data per-day, then Postgres must ensure that there are no rows in the new table that fall outside the boundaries of a given date range that you intend to attach the table with. This blog post provide a simple approach to address this problem with some plpgsql functions that you can quickly and easily adapt to your needs.
There is no one size fits all solution for Partitioning so you will likely have to modify this example to suit your needs. Read the official Table Partitioning Docs so that you understand all the issue involved. Partitioning can be a complex subject, but hopefully this code will get you started down the road to high scalability with very large data sets!
Creating Parent Tables
The example model shown here is a "chat" app, where there is a table of "chats" that act as a container for a bunch of chat messages.
Since user representation is a highly application specific concept, I leave it as an exercise to you how you want to associated these messages with any kind of user system. A likely approach would be to add foreign key references to the chats table that contain the ids of the parties of the chat. For simple person to person chats, this could be as simple as two columns, for multi-party chats, you’ll have to come up with a many-to-many join table that relates chats to participants.
_28BEGIN;_28CREATE SCHEMA app;_28_28CREATE TABLE app.chats(_28 id bigserial,_28 created_at timestamptz NOT NULL DEFAULT now(),_28 PRIMARY KEY (id, created_at) -- the partition column must be part of pk_28 ) PARTITION BY RANGE (created_at);_28_28CREATE INDEX "chats_created_at" ON app.chats (created_at);_28_28CREATE TABLE app.chat_messages(_28 id bigserial,_28 created_at timestamptz NOT NULL,_28 chat_id bigint NOT NULL,_28 chat_created_at timestamptz NOT NULL,_28 message text NOT NULL,_28 PRIMARY KEY (id, created_at),_28 FOREIGN KEY (chat_id, chat_created_at) -- multicolumn fk to ensure_28 REFERENCES app.chats(id, created_at)_28 ) PARTITION BY RANGE (created_at);_28_28CREATE INDEX "chat_messages_created_at" ON app.chat_messages (created_at);_28--_28-- need this index on the fk source to lookup messages by parent_28--_28CREATE INDEX "chat_messages_chat_id_chat_created_at"_28 ON app.chat_messages (chat_id, chat_created_at);
In this model, chats are partitioned by their creation data, this can be seen with the PARTITION BY RANGE clause. We will be creating a new partition for every day, this means that every day a new table will be created for "today's" chat messages. Without partitioning, every day queries to the table would get slower and slower, but with partitioning, the query times remain consistent. Both the chats and chat_messages tables will be partitioned by day. This makes the model fairly simple, but there is a wrinkle, chats can span multiple days, so that's something to keep in mind if you want to keep your data consistent.
Another detail is that the primary key for the chats and chat_messages tables have two columns. This is called a "composite" primary key. This is important because the job of a primary key is to uniquely identify the row, and in the case of a partitioned table it must also uniquely identity the partition. So the partitioned column created_at must be part of the primary key. This is an important structural requirement for partitioning, and it allows Postgres to quickly work with partitioned data, since Postgres always knows which partition table any given primary key will be stored it, it does not have to check all partitions on every operation, which would be prohibitively slow.
Note that this composite primary keys mean that any foreign keys that reference it must also be composite. This can be seen in the FOREIGN KEY clause in the CREATE TABLE statement for chat_messages. This can be tricky because even though it is a totally normal and common SQL pattern that has existed in Postgres and other databases for decades, many ORM like tools in various languages still do not understand or support the notion of composite keys. If this is the case for you, you may want to reconsider using a tool that does not understand standard SQL patterns like this. Powerful ORMs like sqlalchemy have no problem with composite keys, but even popular tools like Django do not support them, in fact in Django, there is an 18 year old ticket on the issue of supporting composite keys.
Finally note there is a CREATE INDEX statement that creates an index on the foreign key relationship in the chat_messages table. This is to ensure that looking up a chat_messages row from a chats row is fast, otherwise, the chat_messages table would have to be scanned, which is definitely something to avoid!
Creating Dynamic Child Tables
Now that we have our parent tables created, it's time to make some partitions! There are two steps to this process, so I have broken them into two PROCEDURE objects for each table. Postgres procedures are like functions, but they cannot be used in many contexts that function can be used such as RLS policies, computed indexes, default expressions, etc. They can only be called with the CALL procedure_name(args) syntax, to avoid accidental misuse. Procedures can also take part in transaction control which we’ll get into a little later in this post.
A complete code example is shown below for both the chats and chat_messages tables, so I’ll only be explaining the partitioning code for the chats table, they are both very similar so you should have no problem adapting this pattern to one or more tables in your database.
In order to create new partitions, we need to know the day to create the table for, this is the only argument to the procedure partition_day. Also we will be creating new tables with the day as part of the child partition table name, so we need to execute "dynamic" SQL. This is done with the EXECUTE keyword that will execute of string of SQL code. Because we have to format that string, we use the format() function to render the SQL string that is executed, this is meta-programming in Postgres! It's not pretty but it works great, and in this case it exactly accomplishes our goal.
Note how the child partitions are created using the LIKE clause so they get the exact schema of the parent table, and the clauses INCLUDING DEFAULTS INCLUDING CONSTRAINTS means the child tables get their own copies of the parent table's default values and constraints like foreign keys.
_14--_14-- Function creates a chats partition for the given day argument_14--_14CREATE OR REPLACE PROCEDURE app.create_chats_partition(partition_day date)_14 LANGUAGE plpgsql AS_14$$_14BEGIN_14 EXECUTE format(_14 $i$_14 CREATE TABLE IF NOT EXISTS app."chats_%1$s"_14 (LIKE app.chats INCLUDING DEFAULTS INCLUDING CONSTRAINTS);_14 $i$, partition_day);_14END;_14$$;
In the full code listing, there is a similar function create_chat_messages_partition() that does the same thing for the chat_messages tables.
Once we have created our child partition tables using the create_chats_partition() procedure, it's time to index and attach those child tables to the parent.
Some important details below, primary keys are added after the data is loaded, this is so the index creation for those keys happens as quickly as possible. Also as noted above, a CHECK constraint is added to the child tables to ensure they do not violate the parent tables PARTITION BY RANGE constraint, this avoid any unnecessary EXCLUSIVE ACCESS locking on the parent tables when they are attached. This type of lock causes downtime because it blocks all access to a table, including SELECT queries. For hundreds of millions of rows of data which could take several hours to copy, you can’t afford to have that long of a downtime of your application.
Avoiding this locking time is an important optimization to make sure you can do the migration from the large table without causing downtime by blocking queries on the parent table. Since the check constraint exactly matches the partition constraint Postgres knows that it can attach the table without having to lock it and scan it for validity. The check constraint already proves the validity of the data in the new child partition, so Postgres doesn’t have to re-prove it at attachment time and can attach the new child partition without blocking any other queries.
After loading the data, you may also create any other indexes needed for the application, like the foreign key index on chat_messages we discussed previously. It’s always faster to create indexes after bulk loading data into a table, than to create the indexes first before loading the data, since the indexes slow down each insert more than the total time it takes to scan the table and create an index. This is another important optimization that speeds up the copying process.
Finally the magic happens, ATTACH PARTITION ... FOR VALUES FROM <low> TO <high> is used to attach the new child partition table to the parent. Since all constraints are known to be verified with the primary key and CHECK constraints, this will happen without locking. Next, the newly created indexes are also attached with ALTER INDEX ... ATTACH PARTITION. Finally, the CHECK constraints that were so helpful to avoid table locking are now no longer necessary, so they can be dropped with ALTER TABLE ... DROP CONSTRAINT.
_41CREATE OR REPLACE PROCEDURE app.index_and_attach_chats_partition(partition_day date)_41 LANGUAGE plpgsql AS_41$$_41BEGIN_41 EXECUTE format(_41 $i$_41 -- now that any bulk data is loaded, setup the new partition table's pks_41 ALTER TABLE app."chats_%1$s" ADD PRIMARY KEY (id, created_at);_41_41 -- adding these check constraints means postgres can_41 -- attach partitions without locking and having to scan them._41 ALTER TABLE app."chats_%1$s" ADD CONSTRAINT_41 "chats_partition_by_range_check_%1$s"_41 CHECK ( created_at >= DATE %1$L AND created_at < DATE %2$L );_41_41 -- add more partition indexes here if necessary_41 CREATE INDEX "chats_%1$s_created_at"_41 ON app."chats_%1$s"_41 USING btree(created_at)_41 WITH (fillfactor=100);_41_41 -- by "attaching" the new tables and indexes *after* the pk,_41 -- indexing and check constraints verify all rows,_41 -- no scan checks or locks are necessary, attachment is very fast,_41 -- and queries to parent are not blocked._41 ALTER TABLE app.chats_41 ATTACH PARTITION app."chats_%1$s"_41 FOR VALUES FROM (%1$L) TO (%2$L);_41_41 -- You now also "attach" any indexes you made at this point_41 ALTER INDEX app."chats_created_at"_41 ATTACH PARTITION app."chats_%1$s_created_at";_41_41 -- Droping the now unnecessary check constraint they were just needed_41 -- to prevent the attachment from forcing a scan to do the same check_41 ALTER TABLE app."chats_%1$s" DROP CONSTRAINT_41 "chats_partition_by_range_check_%1$s";_41 $i$,_41 partition_day, (partition_day + interval '1 day')::date);_41END;_41$$;
Again, there is a full code listing below that shows a similar procedure for index_and_attach_chat_messages_partition.
Progressively Copying Data from the Large Tables
Now that the partition creation and attachment code is in place, it’s time to create one last set of procedures for copying the data over from the old “Large Table” to the new partitioning scheme. This is a procedure that pretty much just does a simple INSERT of the new data that is SELECTed from the old data.
Something worth noting is that the selected data is ORDER BY the created_at column. This means that all the rows that are inserted into the new partition are naturally ordered by their creation date, this tends to improve cache efficiency by keeping recent messages close together in the same database block files:
_22--_22-- Function copies one day's worth of chats rows from old "large"_22-- table new partition. Note that the copied data is ordered by_22-- created_at, this improves block cache density._22--_22CREATE OR REPLACE PROCEDURE app.copy_chats_partition(partition_day date)_22 LANGUAGE plpgsql AS_22$$_22DECLARE_22 num_copied bigint = 0;_22BEGIN_22 EXECUTE format(_22 $i$_22 INSERT INTO app."chats_%1$s" (id, created_at)_22 SELECT id, created_at FROM chats_22 WHERE created_at::date >= %1$L::date AND created_at::date < (%1$L::date + interval '1 day')_22 ORDER BY created_at_22 $i$, partition_day);_22 GET DIAGNOSTICS num_copied = ROW_COUNT;_22 RAISE NOTICE 'Copied % rows to %', num_copied, format('app."chats_%1$s"', partition_day);_22END;_22$$;
Putting it all together: Creating, Copying, Indexing, Attaching
Now the final procedure we need is a wrapper that puts it all together, creating a partition, copying the old data into the new table, indexing the new table, and then attaching it to the parent.
The way this is going to work is that a procedure will create partitions for a whole range of days, and copy over each day one by one, calling COMMIT between each day so that the new table grows incrementally without blocking or locking other database sessions. Note that this procedure works backwards from the newest chats to the oldest (this is the interval '-1 day' argument to generate_series()). So that the new tables can be immediately useful even as you are still loading old data. As above, we’ll just show the example procedure for load_chats_partitions().
_32--_32-- Wrapper function to create, copy, index and attach a given day._32--_32CREATE OR REPLACE PROCEDURE app.load_chats_partition(i date)_32 LANGUAGE plpgsql AS_32$$_32BEGIN_32 CALL app.create_chats_partition(i);_32 CALL app.copy_chats_partition(i);_32 CALL app.index_and_attach_chats_partition(i);_32END;_32$$;_32--_32-- This procedure loops over all days in the old table, copying each day_32-- and then commiting the transaction._32--_32CREATE OR REPLACE PROCEDURE app.load_chats_partitions()_32 LANGUAGE plpgsql AS_32$$_32DECLARE_32 start_date date;_32 end_date date;_32 i date;_32BEGIN_32 SELECT min(created_at)::date INTO start_date FROM chats;_32 SELECT max(created_at)::date INTO end_date FROM chats;_32 FOR i IN SELECT * FROM generate_series(end_date, start_date, interval '-1 day') LOOP_32 CALL app.load_chats_partition(i);_32 COMMIT;_32 END LOOP;_32END;_32$$;
Notice how that the COMMIT statement happens inside the loop after every create, copy, and attach procedure. This allows other sessions to see the new data as it’s being committed so that the new tables are usable even as the old data is being loaded.
And finally, it’s time to kick off the whole process by calling the load_ procedures:
_10CALL app.load_chats_partitions();_10CALL app.load_chat_messages_partitions();
Setting up a Daily Cron Job to Create Partitions
This old school but simple tool will run a scheduled "job" every night at 23:00, one hour before midnight to create the partition for the next day. I'll leave it as an exercise to you if want to try and elaborate this a bit and ensure a whole weeks worth of partitions are created in advance, this would give you a bit more leeway to avoid downtime if the cron job happened to fail, giving you several days to solve the problem instead of one hour.
_15--_15-- This procedure will be used by pg_cron to create both new_15-- partitions for "today"._15--_15CREATE OR REPLACE PROCEDURE app.create_daily_partition(today date)_15 LANGUAGE plpgsql AS_15$$_15BEGIN_15 CALL app.create_chats_partition(today);_15 CALL app.create_chat_messages_partition(today);_15END;_15$$;_15_15SELECT cron.schedule('new-chat-partition', '0 23 * * *', 'CALL app.create_daily_partition(now()::date + 'interval 1 day')');_15COMMIT;
Complete Example Code
And that's it! While there is some complexity, I hope this example has given you some ideas on how you too can partition your data for optimal query performance. There are many ways to slice this problem depending on your needs, while I showed one simple common approach to partition time series data by date range, there are a lot of other approaches and I suggest you go over the official Postgres Table Partitioning documentation to see how other patterns may apply to your situation.
Full code example: https://github.com/supabase/supabase/tree/master/examples/enterprise-patterns/supachat